Computer Science
Data Representation
Program Design
Hardware & Software
Networks
Databases
Data Structures
Algorithms
Other
![]()


Computer Science
Networks 2
Thin & Thick Clients
A network where most applications are run on the client computer is called a thick-client or rich-client network. In such cases, the specification of the client will affect performance.
In a thin-client network all processing takes place on the central server. The server will be a more powerful machine than the clients. The client machines in such a network would normally not be very powerful - the factor that often leads to a thin-client solution. Thin-client machines do not require local backing storage since all applications and data are stored on the server.
Peer-To-Peer Networks
A peer-to-peer network has no dedicated server. The workstations are equal and perform the functions of both client and server in the network. The user of each computer determines the resources which can be shared. Where passwords are used, they are specific to each machine.
Peer-to-peer networks work best with small numbers of users. They are not the most secure networks so would not be used in scenarios that require high security. Since they are less flexible than client-server networks, this type of network would not be best to use when there is a chance that more workstations will need to be added as time passes.
P2P Networks
Peer-to-peer protocols are used on the Internet for file sharing. When a file is shared, the source breaks the file into small chunks and shares these out among the peers requesting the file. The peer then becomes the source for the chunk that they have received. In this way, the original source file is sent out only once from the peer which stores it. As a result, the bandwidth requirement for the source is reduced.
Client-Server Networks
In client-server networks, client devices make requests for network services to servers. Multiple servers may be used for different services. A large network may have a file server, print server, email server and other servers dedicated to functions such as back-up and recovery.
In a client-server network, files are stored on the server which provides the client with access to the relevant portion of the backing store based on the user currently logged onto the network. All of the files can be stored on one array of hard drives and clients usually have a drive letter mapped to their portion of the backing store. Back-up can be carried out centrally for all users.
Users typically use the same password to access any network resource, meaning they can use different workstations and still have access to the same software and files.
Web 2.0
This term gets thrown around quite a bit. Generally, the term refers to the approach to using the WWW that has arisen over recent years. Blogging tools, search engines and social networks are all examples of Web 2.0.
Web Services
Software as a service (SaaS) is an approach to software deployment that characterises Web 2.0.
Web services are applications that are hosted as a service and accessible via the Internet. This can include simple applications and gadgets for the desktop or complete suites of applications. Cloud computing, where a PC's software and data are held online depends on this approach.
Ajax is one technology used in Web 2.0. It is a technology which allows pages to update sections of their content using programs or data held on a web server but without reloading the entire page. This makes the experience of using the software more similar to that of the thick-client and reduces the delay between operations.
Wireless Networking
Wireless networks use radio signals to connect to Wireless Access Points (WAPs). The standard is called Wi-Fi.
Wireless networks are typically slower than wired networks and, because of the danger of interception, have different security issues to wired networks.
Bluetooth
Bluetooth is a wireless protocol for exchanging data over short distances. It was designed for mobile devices like telephones and as an alternative to cables for connecting devices.
Routers
The information used to get packets to their destinations is contained in routing tables kept by each router connected to the Internet. Routers are packet switches. A router is usually connected between networks to route packets between them. Each router knows about it's sub-networks and which IP addresses they use. The router usually doesn't know what IP addresses are 'above' it.
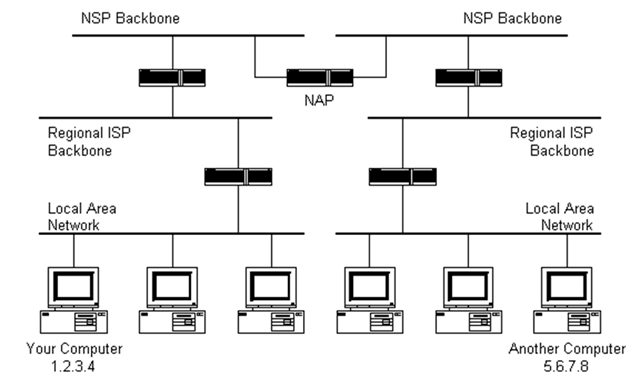
The black boxes connecting the backbones are routers. The larger NSP backbones at the top are connected at a NAP. Under them are several sub-networks, and under them, more sub-networks.
When a packet arrives at a router, the router checks the destination address that wit was given when it was created. Then the router checks its routing table. If it has the address of the network that contains the destination address, the packet is sent to that network. If it doesn't have the address of the network that contains the IP address in the packet, it sends the packet on a predefined default route, usually up the hierarchy to the next router.
The next router may know the address of the network the packet is heading for. If it does not, it routes the packet up the hierarchy again until either the packet gets sent towards its destination or reaches an NSP.
The routers connected to the NSP backbones hold the largest routing tables. The packet will now be routed towards the correct backbone and will find its way back down the hierarchy to its destination.
Routable & Non-Routable IP Addresses
The allocation of IP addresses is controlled globally by The Internet Assigned Numbers Authority (IANA). The IANA allocates addresses to National or Regional Internet Registries (NIR, RIR). ISPs obtain their allocation of IP addresses from the NIR and allocate them to users.
Such addresses are public or routable.
Private or non-routable addresses are reserved for home, office and school networks. The following IP addresses are used for non-routable addressing,
10.0.0.0 to 10.255.255.255
172.16.0.0 to 172.31.255.255
192.168.0.0 to 192.168.255.255
Gateways
A gateway is needed to connect together two networks using different protocols. The gateway reforms LAN frames into WAN frames before sending.